
آموزش نصب Hadoop #
به پردازش مجموعه دادههای بزرگ در اوبونتو فکر میکنید، اما مطمئن نیستید از کجا شروع کنید؟ برای شروع به سختافزار گرانقیمت یا یک کلاستر پیچیده نیاز ندارید. اگر هدف شما ذخیره و تجزیه و تحلیل حجم عظیمی از دادههای ساختاریافته یا بدون ساختار است، آپاچی هادوپ یک راهحل عملی و مقرونبهصرفه ارائه میدهد. این نرمافزار، هم ذخیرهسازی و هم پردازش را با استفاده از یک مدل برنامهنویسی ساده توزیع میکند و آن را برای حجم کاری دادههای بزرگ حتی در زیرساختهای متوسط ایدهآل میکند.
این راهنما نحوه نصب و اجرای Hadoop روی اوبونتو را به شما آموزش میدهد. شما آن را در حالت شبه توزیعشده روی یک دستگاه واحد راهاندازی خواهید کرد تا بتوانید اصول اولیه را بدون مدیریت چندین سرور یاد بگیرید.
چه از یک دسکتاپ محلی استفاده کنید و چه از یک نمونه سرور مجازی از نوین هاست خریداری کردید ، شما هر مرحله از دستورات و پیکربندی را طی خواهید کرد تا در راهاندازی Hadoop در حالت شبه توزیعشده مهارت پیدا کنید.
هادوپ چیست؟ #
آپاچی هادوپ یک چارچوب متنباز است که برای ذخیره و پردازش حجم زیادی از مجموعه دادهها، چیزی که ما آن را “کلان داده” مینامیم، در میان خوشههایی از رایانهها طراحی شده است. به جای استفاده از یک رایانه بزرگ برای ذخیره و پردازش دادهها، هادوپ امکان خوشهبندی چندین رایانه را برای تجزیه و تحلیل سریعتر مجموعه دادههای عظیم به صورت موازی فراهم میکند. آن را به عنوان یک جعبه ابزار قدرتمند در نظر بگیرید که به بسیاری از ماشینها اجازه میدهد تا با هم کار کنند تا مشکلات دادهای را که برای یک سرور واحد بسیار بزرگ است، حل کنند.
در هسته خود، Hadoop به شما موارد زیر را ارائه میدهد:
- HDFS (سیستم فایل توزیعشدهی هادوپ): این راهکار ذخیرهسازی هادوپ است. این سیستم هوشمندانه فایلهای حجیم را به قطعات کوچکتر تقسیم میکند و آنها را در چندین ماشین پخش میکند و تضمین میکند که حتی اگر سرور از کار بیفتد، دادههای شما ایمن و در دسترس هستند.
- YARN (یکی دیگر از مذاکرهکنندگان منابع): YARN تمام منابع موجود در کلاستر Hadoop شما، مانند CPU و حافظه را مدیریت میکند و تمام وظایفی را که به آن محول میکنید، زمانبندی میکند.
- MapReduce: MapReduce موتور پردازش اصلی Hadoop است. این موتور با شکستن یک کار پردازش داده بزرگ به وظایف کوچکتر، نگاشت آن وظایف در گرههای مختلف برای اجرای موازی و سپس کاهش نتایج به یک خروجی نهایی کار میکند.
هدوپ برای چه مواردی استفاده میشود؟ #
Hadoop ستون فقرات برنامههای بیشماری در حوزه کلانداده است، از جمله:
- تجزیه و تحلیل دادههای بزرگ: زمانی که نیاز به استخراج اعداد از مجموعه دادههای عظیم دارید.
- ساخت انبارهای داده و دریاچههای داده: برای ذخیره و سازماندهی حجم عظیمی از اطلاعات برای استفاده در آینده ضروری است.
- تحلیل لاگ: با بررسی انبوهی از فایلهای لاگ، متوجه میشوید که چه اتفاقی برای سرورهای وب یا برنامههای شما میافتد.
- موتورهای پیشنهاددهنده: تصور کنید نتفلیکس یا آمازون به شما پیشنهاد میدهند که چه چیزی ممکن است در ادامه دوست داشته باشید.
- وظایف یادگیری ماشین: فراهم کردن زیرساخت برای آموزش مدلهای پیچیده هوش مصنوعی روی مجموعه دادههای عظیم.
به طور خلاصه، اگر با حجم زیادی از دادهها سر و کار دارید و به روشی مقیاسپذیر و مقاوم در برابر خطا برای ذخیره و پردازش آنها نیاز دارید، Hadoop راهحل مورد نظر شماست. این ابزار به شما امکان میدهد بینشهای ارزشمندی را از اطلاعاتی استخراج کنید که در غیر این صورت غیرقابل مدیریت خواهند بود.
🇩🇪 سرور مجازی المان 🇩🇪
پیش نیازها #
این راهنما شامل یک نمایش عملی است. برای دنبال کردن مراحل راهاندازی آپاچی هادوپ روی اوبونتو ۲۴.۰۴ در حالت شبهتوزیعشده، مطمئن شوید که موارد زیر را دارید:
- یک سرور مجازی با حداقل ۲ هسته پردازنده، ۴ گیگابایت رم و ۲۰ گیگابایت فضای دیسک خالی.
- امتیازات sudo (یوزر اصلی) .
- کیت توسعه جاوا (JDK) نصب شده باشد (OpenJDK 11 توصیه میشود).
- سرور OpenSSH و کلاینت OpenSSH نصب شده و سرویس SSH در حال اجرا است.
نحوه نصب Hadoop روی اوبونتو ۲۴.۰۴ (حالت شبه توزیع شده) #
در حالت شبه توزیعشده، تمام سرویسهای Hadoop (NameNode، DataNode، ResourceManager، NodeManager) بر روی یک ماشین واحد اجرا میشوند. این تنظیمات به گونهای پیکربندی شده است که از یک خوشه چند گرهای تقلید کند و به شما امکان میدهد عملیات HDFS را آزمایش کنید و برنامههای MapReduce یا YARN را مانند یک خوشه کوچک اجرا کنید. این نقطه شروع ایدهآلی برای یادگیری Hadoop است.
مرحله ۱: بستههای سیستمی را در اوبونتو به روزرسانی کنید #
ابتدا، اگر از راه دور کار میکنید، از طریق SSH به سرور خود متصل شوید . سپس، لیست بستههای سیستم خود را بهروزرسانی کنید تا مطمئن شوید که برای فرآیند نصب آماده است. یک ترمینال باز کنید و دستور زیر را اجرا کنید:
sudo apt update && sudo apt upgrade -y
خروجیHit:1 http://archive.ubuntu.com/ubuntu noble InRelease
...
Fetched 34.0 MB in 14s (2364 kB/s)
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
۶ packages can be upgraded. Run 'apt list --upgradable' to see them.
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Calculating upgrade... Done
The following NEW packages will be installed:
linux-headers-6.8.0-59 linux-headers-6.8.0-59-generic linux-image-6.8.0-59-generic
linux-modules-6.8.0-59-generic linux-tools-6.8.0-59 linux-tools-6.8.0-59-generic
The following packages will be upgraded:
linux-headers-generic linux-headers-virtual linux-image-virtual linux-libc-dev
linux-tools-common linux-virtual
۶ upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
...
Fetched 80.1 MB in 2s (38.5 MB/s)
Selecting previously unselected package linux-headers-6.8.0-59.
...
Setting up linux-virtual (6.8.0-59.61) ...
Processing triggers for man-db (2.12.0-4build2) ...
Processing triggers for linux-image-6.8.0-59-generic (6.8.0-59.61) ...
...
Generating grub configuration file ...
...
done
Scanning processes...
Scanning linux images...
Pending kernel upgrade!
Running kernel version:
۶.۸.۰-۵۸-generic
Diagnostics:
The currently running kernel version is not the expected kernel version 6.8.0-59-generic.
Restarting the system to load the new kernel will not be handled automatically, so you should
consider rebooting.
No services need to be restarted.
...
مرحله ۲: نصب OpenJDK برای Hadoop #
Hadoop بر پایه جاوا ساخته شده است، بنابراین به نصب کیت توسعه جاوا (JDK) نیاز دارید. OpenJDK 11 را با اجرای دستور زیر نصب کنید:
sudo apt install openjdk-11-jdk -y
خروجیReading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
... (a long list of libraries and other necessary files)
Suggested packages:
...
Recommended packages:
...
The following NEW packages will be installed:
... (many dependencies) ... openjdk-11-jdk ... (more dependencies)
۰ upgraded, 92 newly installed, 0 to remove and 0 not upgraded.
Need to get 184 MB of archives.
After this operation, 553 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu noble/main amd64 alsa-topology-conf all 1.2.5.1-2 [15.5 kB]
... (many more Get lines) ...
Fetched 184 MB in 8s (22.9 MB/s)
Extracting templates from packages: 100%
Selecting previously unselected package alsa-topology-conf.
(Reading database ...)
Preparing to unpack .../alsa-topology-conf_1.2.5.1-2_all.deb ...
Unpacking alsa-topology-conf (1.2.5.1-2) ...
... (many more unpacking steps) ...
Setting up libgraphite2-3:amd64 (1.3.14-2build1) ...
Setting up ... (many more setting up steps) ...
Setting up openjdk-11-jdk:amd64 (11.0.27+6~us1-0ubuntu1~24.04) ...
Processing triggers for ...
...
پس از اتمام این کار، نسخه را برای تأیید نصب بررسی کنید:
java --version
شما باید چیزی شبیه به این را ببینید:
خروجیopenjdk 11.0.27 2025-04-15
OpenJDK Runtime Environment (build 11.0.27+6-post-Ubuntu-0ubuntu124.04)
OpenJDK 64-Bit Server VM (build 11.0.27+6-post-Ubuntu-0ubuntu124.04, mixed mode, sharing)
مرحله ۳: ایجاد یک کاربر اختصاصی برای Hadoop #
در مرحله بعد، یک کاربر اختصاصی برای Hadoop ایجاد کنید. این کار به جداسازی مجوزها کمک میکند و مدیریت را آسانتر میکند. یک کاربر با نام دلخواه ایجاد کنید hadoop(در صورت تمایل میتوانید از نام دیگری استفاده کنید):
sudo adduser hadoop
از شما خواسته میشود که یک رمز عبور تنظیم کنید و برخی اطلاعات کاربری اختیاری را ارائه دهید.
خروجیinfo: Adding user `hadoop' ...
info: Selecting UID/GID from range 1000 to 59999 ...
info: Adding new group `hadoop' (1000) ...
info: Adding new user `hadoop' (1000) with group `hadoop (1000)' ...
info: Creating home directory `/home/hadoop' ...
info: Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y
info: Adding new user `hadoop' to supplemental / extra groups `users' ...
info: Adding user `hadoop' to group `users' ...
به کاربر امتیازات sudo بدهید:
sudo usermod -aG sudo hadoop
حالا با استفاده از دستور زیر به hadoopکاربر مورد نظر سوئیچ کنید:
su - hadoop
در صورت درخواست، رمز عبور کاربر را وارد کنید. اکنون باید پیام شما نشان دهد که با نام کاربری وارد سیستم شدهاید hadoop.
خروجیTo run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop@demo:~$
مرحله ۴: پیکربندی SSH بدون رمز عبور #
در مرحله بعد، باید SSH بدون رمز عبور را راهاندازی کنید. Hadoop از SSH برای مدیریت سرویسهای خود در سراسر گرهها (یا در یک گره واحد برای حالت شبه توزیعشده، اتصال به localhost) استفاده میکند.
سرورهای اوبونتو معمولاً کلاینت و سرور SSH را نصب دارند، میتوانید با استفاده از دستور زیر تأیید کنید:
با استفاده از دستورات زیر، نصب کلاینت و سرور SSH را تأیید کنید:
ssh -V
خروجیOpenSSH_9.6p1 Ubuntu-3ubuntu13.11, OpenSSL 3.0.13 30 Jan 2024
systemctl status ssh
خروجی● ssh.service - OpenBSD Secure Shell server
Loaded: loaded (/usr/lib/systemd/system/ssh.service; disabled; preset: enabled)
Active: active (running) since Wed 2025-05-14 04:42:10 EEST; 31min ago
TriggeredBy: ● ssh.socket
Docs: man:sshd(8)
man:sshd_config(5)
Main PID: 1076 (sshd)
Tasks: 1 (limit: 4655)
Memory: 4.1M (peak: 5.3M)
CPU: 154ms
CGroup: /system.slice/ssh.service
└─۱۰۷۶ "sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups"
May 14 04:42:10 demo systemd[1]: Starting ssh.service - OpenBSD Secure Shell server...
May 14 04:42:10 demo sshd[1076]: Server listening on :: port 22.
May 14 04:42:10 demo systemd[1]: Started ssh.service - OpenBSD Secure Shell server.
May 14 04:42:10 demo sshd[1079]: Connection closed by 188.214.133.131 port 37150
May 14 04:52:19 demo sshd[1125]: Accepted password for root from 102.90.80.130 port 2768 ssh2
May 14 04:52:19 demo sshd[1125]: pam_unix(sshd:session): session opened for user root(uid=0) by>
May 14 05:06:19 demo sshd[7904]: Accepted password for root from 102.90.80.130 port 2636 ssh2
May 14 05:06:19 demo sshd[7904]: pam_unix(sshd:session): session opened for user root(uid=0) by>
اگر فعال نیست یا سرویس پیدا نشد، باید آن را نصب یا راهاندازی کنید.
اگر SSH از قبل نصب نشده است، میتوانید با استفاده از دستورات زیر آن را نصب و فعال کنید:
sudo apt install openssh-server openssh-client -y
sudo systemctl enable ssh
اکنون، یک جفت کلید SSH ایجاد کنید:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
خروجیGenerating public/private rsa key pair.
Created directory '/home/hadoop/.ssh'.
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:kin50YdBqah1j/RG6KeGAF6zKIppkxEOU14vcBiuEuo hadoop@demo
The key's randomart image is:
+---[RSA 3072]----+
| .o .. |
| .+ o .. |
|.o.+ o o. |
|=+.o+.*+.o |
|Bo+o====S . |
|+=o. ooo=. |
|+Eo. ..+ |
|++ . o |
|. . . |
+----[SHA256]-----+
شما باید کلید عمومی تولید شده را به لیست کلیدهای مجاز برای کاربر اضافه کنید hadoopتا بتواند localhostبدون رمز عبور وارد سیستم شود (). این کار را با استفاده از دستور زیر انجام دهید:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
سپس مجوزهای لازم را برای فایل تنظیم کنید تا مطمئن شوید فقط صاحب فایل میتواند آن را بخواند و بنویسد:
chmod 600 ~/.ssh/authorized_keys
حالا بررسی کنید که آیا میتوانید بدون درخواست رمز عبور hadoopبه SSH متصل شوید :localhost
ssh localhost
اولین باری که متصل میشوید، ممکن است پیامی مانند «احراز هویت میزبان ‘localhost (127.0.0.1)’ قابل تشخیص نیست. اثر انگشت کلید ED25519 از نوع SHA256:xxxxxxxxxxxxxxxxxxxxxxxxxxx است. آیا مطمئن هستید که میخواهید به اتصال ادامه دهید (بله/خیر/[اثر انگشت])؟» را تایپ کرده yesو Enter را فشار دهید. سپس باید بدون درخواست رمز عبور وارد سیستم شوید.
خروجیThe authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:ImVq/XOAViXspPZg1grGdz0E1Q8u1OZ9Cdsk45HAuWY.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
Welcome to Ubuntu 24.04.2 LTS (GNU/Linux 6.8.0-58-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/pro
System information as of Mon May 12 20:47:26 EEST 2025
System load: 0.0 Processes: 137
Usage of /: 3.3% of 76.45GB Users logged in: 1
Memory usage: 8% IPv4 address for eth0: 5.199.161.101
Swap usage: 0%
Expanded Security Maintenance for Applications is not enabled.
۰ updates can be applied immediately.
Enable ESM Apps to receive additional future security updates.
See https://ubuntu.com/esm or run: sudo pro status
*** System restart required ***
Last login: Mon May 12 20:29:21 2025 from 105.113.10.163
پس از تأیید ورود بدون رمز عبور، از جلسه SSH خارج شوید تا به اعلان اصلی خود بازگردید:
exit
مرحله ۵: دانلود و استخراج Hadoop #
اکنون، همچنان به عنوان hadoopکاربر، آپاچی هادوپ را دانلود و استخراج خواهید کرد.
یک مرورگر وب باز کنید و به صفحه رسمی انتشارهای آپاچی هادوپ بروید . آخرین نسخه باینری پایدار را پیدا کنید و آدرس آن را کپی کنید. سپس، آن را با استفاده از دانلود کنید wget.
cd ~
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz
خروجی--۲۰۲۵-۰۵-۱۲ ۲۰:۵۵:۰۶-- https://dlcdn.apache.org/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz
Resolving dlcdn.apache.org (dlcdn.apache.org)... 151.101.2.132, 2a04:4e42::644
Connecting to dlcdn.apache.org (dlcdn.apache.org)|151.101.2.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 974002355 (929M) [application/x-gzip]
Saving to: ‘hadoop-3.4.1.tar.gz’
hadoop-3.4.1.tar.gz 100%[===============================>] 928.88M 72.4MB/s in 12s
۲۰۲۵-۰۵-۱۲ ۲۰:۵۵:۲۶ (۸۰.۴ MB/s) - ‘hadoop-3.4.1.tar.gz’ saved [974002355/974002355]
پس از اتمام دانلود، فایل دانلود شده را از حالت فشرده خارج کنید:
tar -xzf hadoop-*.tar.gz
معمولاً Hadoop را در یک مکان استاندارد مانند … قرار میدهند /usr/local/. پوشه استخراج شده را به آنجا منتقل کنید و hadoopبرای سادگی، نام آن را به … تغییر دهید.
sudo mv hadoop-3.4.1 /usr/local/hadoop
اکنون مطمئن شوید که hadoopمالک /usr/local/hadoopدایرکتوری و محتویات آن هستید:
sudo chown -R hadoop:hadoop /usr/local/hadoop
مرحله ۶: پیکربندی متغیرهای محیطی Hadoop #
شما باید چندین متغیر محیطی را تنظیم کنید تا سیستم شما و Hadoop بتوانند فایلها و پیکربندیهای لازم را پیدا کنند.
.bashrcفایل را برای ویرایش باز کنید :
nano ~/.bashrc
خطوط زیر را به انتهای فایل اضافه کنید. این متغیرها به سیستم شما میگویند که نصب Hadoop شما در کجا قرار دارد و توسط اسکریپتهای Hadoop استفاده میشوند.
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
در مرحله بعد، باید متغیرهای محیطی را برای جاوا تنظیم کنید تا سایر برنامهها بتوانند آن را پیدا کنند. برای انجام این کار، به ~/.bashrcفایل دسترسی پیدا کنید.
sudo nano ~/.bashrc
خطوط زیر را اضافه کنید که JAVA_HOMEمتغیر محیطی را مشخص میکنند.
export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))
export PATH=$PATH:$JAVA_HOME/bin
تغییرات را ذخیره کرده و خارج شوید. سپس ~/.bashrcفایل را برای اعمال تغییرات ایجاد شده، سورس کنید.
source ~/.bashrc
مطمئن شوید که JAVA_HOMEمتغیر محیطی به درستی تنظیم شده است.
echo $JAVA_HOME
خروجی/usr/lib/jvm/java-11-openjdk-amd64
``
Save and close the file (`Ctrl+X`, then `Y`, then `Enter`).
You can verify your Hadoop installation using:
```bash command
hadoop version
خروجیHadoop 3.4.1
Source code repository https://github.com/apache/hadoop.git -r 4d7825309348956336b8f06a08322b78422849b1
Compiled by mthakur on 2024-10-09T14:57Z
Compiled on platform linux-x86_64
Compiled with protoc 3.23.4
From source with checksum 7292fe9dba5e2e44e3a9f763fce3e680
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.4.1.jar
تأیید کنید که HADOOP_HOMEبه درستی تنظیم شده است:
echo $HADOOP_HOME
خروجی/usr/local/hadoop
در مرحله بعد، باید مطمئن شوید که Hadoop محل نصب جاوای شما را میداند. اکنون، به طور صریح آن را JAVA_HOMEدر پیکربندی Hadoop تنظیم کنید. hadoop-env.shفایل را برای ویرایش باز کنید:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
به دنبال خطی بگردید که با شروع میشود # export JAVA_HOME=. آن را از حالت کامنت خارج کنید (علامت را حذف کنید ) و آن را به مسیر #خود تنظیم کنید :JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
فایل را ذخیره کنید و ببندید ( Ctrl+X، سپس Y، سپس Enter).
مرحله ۷: پیکربندی فایلهای Hadoop XML برای حالت شبه توزیعشده #
در این مرحله، فایلهای XML اصلی واقع در را پیکربندی خواهید کرد $HADOOP_HOME/etc/hadoop/. این فایلها نحوه عملکرد Hadoop را در حالت شبه توزیعشده تعیین میکنند.
با ایجاد دایرکتوریهایی که Hadoop برای ذخیرهسازی دادههای HDFS استفاده خواهد کرد، شروع کنید:
mkdir -p $HADOOP_HOME/hdfs/namenode
mkdir -p $HADOOP_HOME/hdfs/datanode
سپس مالکیت دایرکتوری و محتویات آن را به hadoopکاربر اختصاص دهید.
sudo chown -R hadoop:hadoop $HADOOP_HOME/hdfs
حالا، بیایید فایلهای پیکربندی XML را ویرایش کنیم.
- هسته-سایت.xmlفایل را باز کنید
core-site.xml:nano $HADOOP_HOME/etc/hadoop/core-site.xmlتگهای خالی را
<configuration></configuration>با تگهای زیر جایگزین کنید:<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> <description>The default file system URI</description> </property> </configuration>hdfs://localhost:9000به Hadoop میگوید که از HDFS که رویlocalhostپورت اجرا میشود استفاده کند۹۰۰۰.
- hdfs-site.xml
hdfs-site.xmlفایل را با ویرایشگر نانو باز کنید :nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlبین
<configuration>تگها، موارد زیر را اضافه کنید:<configuration> <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.name.dir</name> <value>file:///usr/local/hadoop/hdfs/namenode</value> <description>Path on the local filesystem where the NameNode stores the namespace and transaction logs.</description> </property> <property> <name>dfs.data.dir</name> <value>file:///usr/local/hadoop/hdfs/datanode</value> <description>Path on the local filesystem where the DataNode stores its blocks.</description> </property> </configuration>این پیکربندی، یک محیط HDFS تک نسخهای را با استفاده از دایرکتوریهای دادهای که قبلاً ایجاد کردهاید، راهاندازی میکند.
- نقشه سایت.xml
mapred-site.xmlفایل را برای ویرایش باز کنید :nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlتگهای خالی
<configuration></configuration>را با موارد زیر جایگزین کنید:<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>The runtime framework for MapReduce. Can be local, classic or yarn.</description> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> </configuration>این کار MapReduce را قادر میسازد تا روی YARN اجرا شود و متغیرهای محیطی مناسب را تنظیم کند.
- yarn-site.xmlدر نهایت،
yarn-site.xmlفایل را ویرایش کنید:nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlبین
<configuration>تگها، موارد زیر را اضافه کنید:<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>Auxilliary services required by the NodeManager.</description> </property> </configuration>این سرویس shuffle را فعال میکند که برای اجرای کارهای MapReduce روی YARN ضروری است.
مرحله ۸: فرمت HDFS NameMode #
قبل از اینکه بتوان از HDFS استفاده کرد، NameNode باید فرمت شود. این مرحله سیستم فایل HDFS را مقداردهی اولیه کرده و ساختار دایرکتوری تعریف شده در . شما را تنظیم میکند hdfs-site.xml.
همچنان که هست hadoop، اجرا کنید:
hdfs namenode -format
این دستور را فقط یک بار در طول راهاندازی اولیه اجرا کنید. قالببندی مجدد، تمام دادههای ذخیره شده در HDFS را پاک میکند.
این دستور چندین پیام لاگ (log) را نمایش میدهد. در انتها، به دنبال خطوط تأیید مانند موارد زیر باشید: INFO common.Storage: Storage directory /usr/local/hadoop/data/namenode has been successfully formatted.و همچنین:INFO namenode.NameNode: SHUTDOWN_MSG: Shutting down NameNode at ...
خروجیWARNING: /usr/local/hadoop/logs does not exist. Creating.
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۰,۸۵۶ INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = demo/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.4.1
STARTUP_MSG: classpath = /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/curator-framework-5.2.0.jar:... (truncated for brevity) ...
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r 4d7825309348956336b8f06a08322b78422849b1; compiled by 'mthakur' on 2024-10-09T14:57Z
STARTUP_MSG: java = 11.0.27
************************************************************/
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۰,۸۷۳ INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۱,۰۷۲ INFO namenode.NameNode: createNameNode [-format]
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۰۰۳ INFO namenode.NameNode: **Formatting using clusterid: CID-8e15e115-84e9-4400-8014-68ad4b72a38f**
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۰۸۰ INFO namenode.FSEditLog: Edit logging is async:true
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۱۴۲ INFO namenode.FSNamesystem: KeyProvider: null
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۱۴۵ INFO namenode.FSNamesystem: fsLock is fair: true
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۱۸۲ INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۱۸۳ INFO namenode.FSNamesystem: isPermissionEnabled = true
... (configuration details and GSet info omitted for brevity) ...
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۹۶۳ INFO namenode.FSImage: Allocated new BlockPoolId: BP-42078627-127.0.1.1-1747090602953
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۲,۹۹۹ INFO common.Storage: **Storage directory /usr/local/hadoop/hdfs/namenode has been successfully formatted.**
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۳,۰۵۶ INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۳,۲۶۳ INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds .
۲۰۲۵-۰۵-۱۳ ۰۱:۵۶:۴۳,۳۴۲ INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at demo/127.0.1.1
************************************************************/
مرحله ۹: شروع سرویسهای Hadoop #
با تکمیل پیکربندی، زمان شروع سرویسهای اصلی Hadoop فرا رسیده است. Hadoop اسکریپتهای مفیدی را برای شروع سرویسهای HDFS و YARN ارائه میدهد.
اسکریپت زیر را برای شروع NameNode، DataNode و SecondaryNameNode اجرا کنید:
start-dfs.sh
خروجیStarting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [demo]
demo: Warning: Permanently added 'demo' (ED25519) to the list of known hosts.
سپس، ResourceManager و NodeManager را اجرا کنید:
start-yarn.sh
خروجیStarting resourcemanager
Starting nodemanagers
پس از اجرای هر دو اسکریپت، سرویسهای Hadoop شما باید فعال و در حال اجرا باشند.
مرحله ۱۰: تأیید کنید که سرویسهای Hadoop در حال اجرا هستند #
برای تأیید اینکه همه سرویسهای Hadoop با موفقیت شروع به کار کردهاند، از jpsدستور زیر استفاده کنید. این ابزار تمام فرآیندهای جاوا را که در حال حاضر روی سیستم در حال اجرا هستند، فهرست میکند.
jps
باید خروجی مشابه این را ببینید (شناسههای فرآیند متفاوت خواهد بود):
خروجی۹۳۰۰ NameNode
۱۰۳۷۳ Jps
۹۴۳۵ DataNode
۱۰۰۲۹ NodeManager
۹۸۸۵ ResourceManager
۹۶۴۷ SecondaryNameNode
مشاهده این فرآیندها تأیید میکند که Hadoop به درستی اجرا میشود.
مرحله ۱۱: دسترسی به رابطهای کاربری وب #
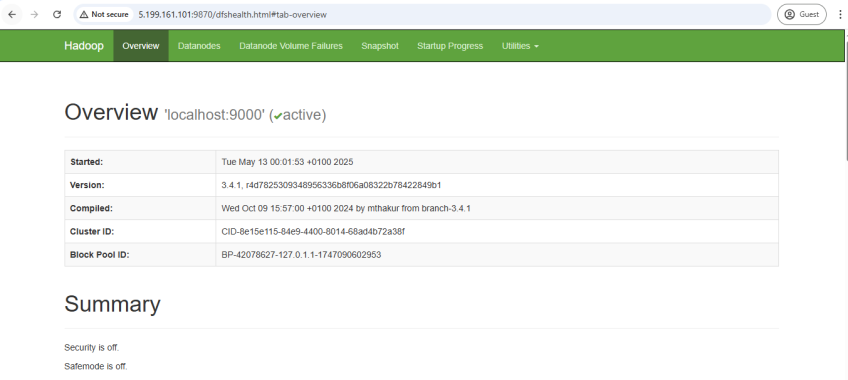
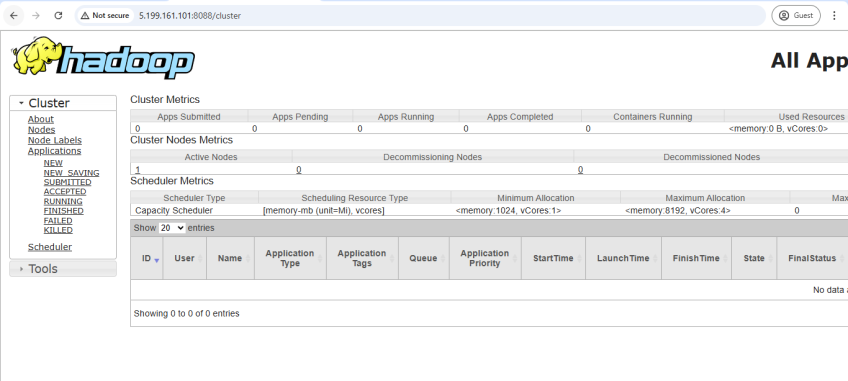
Hadoop رابطهای وب داخلی را برای کمک به شما در نظارت بر سلامت و فعالیت خوشه خود فراهم میکند. میتوانید وضعیت، گرهها، میزان استفاده از سیستم فایل و برنامههای در حال اجرا را به صورت بلادرنگ مشاهده کنید.
یک مرورگر وب باز کنید و به رابطهای وب Hadoop بروید:
- اگر Hadoop را به صورت محلی روی دستگاه خود اجرا میکنید، از دستور زیر استفاده کنید:
- رابط کاربری NameNode در HDFS: http://localhost:9870
- رابط کاربری YARN ResourceManager: http://localhost:8088
- اگر Hadoop شما روی یک سرور راه دور (مانند یک نمونه سرور مجازی نوین هاست ) اجرا میشود، آن را
localhostبا آدرس IP عمومی سرور خود جایگزین کنید:- رابط کاربری NameNode در HDFS:
http://<server-ip>:9870 - رابط کاربری YARN ResourceManager:
http://<server-ip>:8088
- رابط کاربری NameNode در HDFS:
پس از باز کردن این URLها، باید داشبوردهایی را مشاهده کنید که سلامت خوشه، وضعیت گره و برنامههای در حال اجرا را نشان میدهند (در ابتدا اگر هنوز هیچ کاری ارسال نشده باشد، خالی است).
مرحله ۱۲: متوقف کردن سرویسهای Hadoop #
وقتی کارتان تمام شد، میتوانید سرویسهای Hadoop را متوقف کنید.
با اجرای دستور زیر، سرویسهای YARN را متوقف کنید:
stop-yarn.sh
شما باید چیزی شبیه به این را ببینید:
خروجیStopping nodemanagers
Stopping resourcemanager
سرویسهای HDFS را با استفاده از دستور زیر متوقف کنید:
stop-dfs.sh
خروجی مورد انتظار:
خروجیStopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [demo]
jpsبرای تأیید خاتمه یافتن تمام فرآیندهای Hadoop، دوباره اجرا کنید :
jps
شما فقط باید Jpsفرآیند را در خروجی ببینید، مانند این:
خروجی۱۸۷۰۴ Jps
نتیجه گیری #
اکنون شما با موفقیت آپاچی هدوپ را در حالت شبه توزیعشده روی سرور اوبونتو ۲۴.۰۴ خود نصب و پیکربندی کردهاید. از نصب وابستگیها و پیکربندی متغیرهای محیطی گرفته تا راهاندازی سرویسهای اصلی و تأیید همه چیز با رابطهای کاربری وب، اکنون یک مینیکلاستر کاربردی دارید که روی یک دستگاه واحد اجرا میشود. این تنظیمات برای یادگیری نحوه عملکرد هدوپ در زیر کاپوت و اجرای کارهای MapReduce در مقیاس کوچکتر بدون نیاز به چندین سرور ایدهآل است.
حالا که با اجزای اصلی آشنا هستید، چرا راهاندازی یک کلاستر چندگرهای Hadoop را امتحان نمیکنید؟ این کار به شما تجربه عملی در پردازش دادههای توزیعشده در دنیای واقعی و ارتباط گره به گره میدهد.



