در دنیای مدرن زیرساخت و هاستینگ، داشتن دید دقیق از وضعیت سرور، دیگر یک مزیت نیست — یک ضرورت حیاتی است.
مدیران سیستم و تیمهای DevOps هر روز با هزاران متریک، لاگ و هشدار سر و کار دارند. اما سؤال اینجاست: آیا مانیتورینگ سنتی واقعاً پاسخگوی پیچیدگی امروز است؟
فرض کنید تمام داشبوردهای شما سبز هستند، CPU در حالت نرمال است، ولی کاربران از کندی سایت شکایت میکنند. هیچ هشداری هم فعال نشده. چه اتفاقی افتاده است؟
اینجاست که مفهوم جدیدی به نام Observability (مشاهدهپذیری) وارد میدان میشود.
Observability فراتر از مانیتورینگ است. این مفهوم به شما کمک میکند نهفقط بدانید چه اتفاقی افتاده، بلکه چرا و کجا رخ داده است.
ریشهی Observability از مهندسی کنترل تا DevOps
مفهوم Observability اولینبار در مهندسی کنترل (Control Theory) مطرح شد.
در آن حوزه، سیستمهایی مانند هواپیما یا نیروگاه باید دائماً رصد میشدند، اما نمیشد داخلشان را دید.
مهندسان برای درک وضعیت سیستم فقط به خروجیها نگاه میکردند — مثلاً تغییر دما یا فشار — تا بفهمند درون آن چه میگذرد.
این یعنی:
“اگر بتوانید با مشاهدهی خروجیها، وضعیت داخلی را درک کنید، سیستم شما Observable است.”
همین ایده بعدها به دنیای IT وارد شد. چون سیستمهای نرمافزاری امروزی — بهویژه در معماریهای Cloud و Microservices — هم مثل موتور هواپیما پیچیدهاند و نمیتوان با چند متریک ساده آنها را فهمید.
تفاوت مانیتورینگ و Observability
مانیتورینگ، ابزاری برای پایش وضعیت سیستم است. به کمک آن میفهمیم چه اتفاقی افتاده است؛ مثلاً مصرف CPU بالا رفته یا سرویس MySQL متوقف شده.
اما Observability یک رویکرد تحلیلی است که به ما میگوید چرا اتفاق افتاده و چطور میتوان جلوی تکرار آن را گرفت.
| ویژگی | Monitoring | Observability |
|---|---|---|
| تمرکز | وضعیت فعلی سیستم | درک علت و رفتار درونی |
| دادهها | Metrics محدود | Metrics + Logs + Traces |
| نوع واکنش | واکنشی (بعد از خطا) | تحلیلی و پیشبینیکننده |
| سطح بینش | سطحی | عمیق و علتیاب |
| ابزارها | Zabbix, Prometheus | Grafana, Loki, Tempo, OpenTelemetry |
در حقیقت، مانیتورینگ میگوید چه چیزی اشتباه است، Observability میگوید چرا اشتباه است.
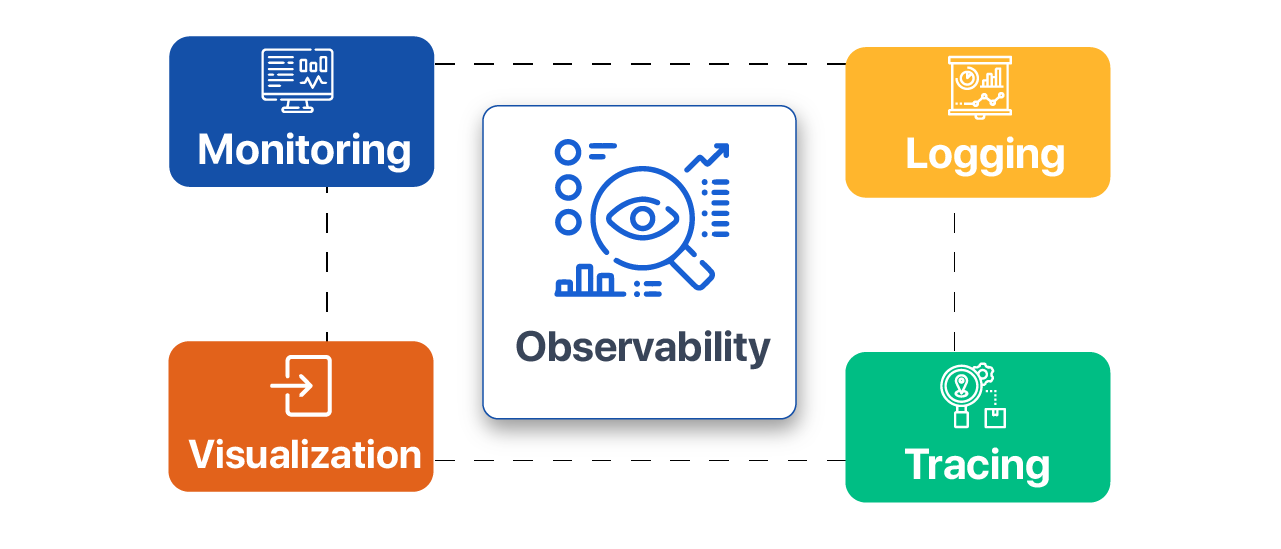
سه ستون اصلی Observability
Metrics (متریکها)
متریکها دادههای عددی دربارهی عملکرد سیستم هستند. مثلاً CPU Usage، Memory Consumption یا Latency.
در مانیتورینگ سنتی، متریکها بهتنهایی برای تصمیمگیری استفاده میشدند. اما در Observability، این دادهها با Logs و Traces ترکیب میشوند تا معنای عمیقتری پیدا کنند.
مثلاً اگر CPU بالا برود، ممکن است علتش یک حلقهی بیپایان در کد یا یک درخواست تکراری از سمت کاربر باشد. بدون دادههای دیگر، نمیتوان تفاوت را تشخیص داد.
برای جمعآوری متریکها معمولاً از Prometheus استفاده میشود و با Grafana آنها را به نمودارهای زنده تبدیل میکنیم.
نمونه دستور ساده در PromQL برای مشاهده میانگین مصرف CPU در ۵ دقیقه اخیر:
avg(rate(node_cpu_seconds_total{mode!="idle"}[5m])) * 100
Logs (لاگها)
لاگها روایت رویدادهای سیستم هستند. هر چیزی که اتفاق میافتد — از خطای PHP تا وضعیت دسترسی nginx — در لاگها ثبت میشود.
Observability از لاگها برای پاسخ به سؤال «چه چیزی دقیقاً در آن لحظه رخ داده؟» استفاده میکند.
بهجای لاگگیری ساده با tail -f, ابزارهایی مثل Loki و Elastic Stack دادههای لاگ را ساختارمند و قابل جستوجو میکنند.
در Loki، لاگها در قالب stream ذخیره میشوند و میتوان آنها را بر اساس labelها (مانند app، host یا namespace) فیلتر کرد.
نمونه query در Loki:
{app="nginx"} |= "error"
این دستور همهی خطاهای nginx را نمایش میدهد.
Traces (ردیابیها)
Trace یعنی مسیر حرکت یک درخواست درون سیستم.
در معماری Microservices، یک درخواست ممکن است از ۱۰ سرویس عبور کند؛ اگر یکی از آنها کند شود، کل سیستم کند میشود.
با ابزارهایی مثل Grafana Tempo یا Jaeger میتوان مسیر دقیق هر درخواست را از ابتدا تا انتها دنبال کرد.
مثلاً میتوانید ببینید درخواست login از nginx به auth-service رفته، سپس database را صدا زده و ۲ ثانیه تأخیر در query رخ داده.
این یعنی ردیابی دقیق علت، نه صرفاً مشاهدهی نتیجه.
Observability در DevOps و Site Reliability Engineering (SRE)
در دنیای DevOps، Observability با مفاهیم SLI، SLO و SLA گره خورده است:
- SLA (Service Level Agreement): توافق با مشتری دربارهی سطح دسترسی (مثلاً ۹۹.۹٪ آپتایم).
- SLO (Service Level Objective): هدف داخلی تیم برای حفظ آن SLA.
- SLI (Service Level Indicator): متریک واقعی اندازهگیریشده (مثلاً میانگین latency).
Observability ابزار رسیدن به این اهداف است.
بدون آن، شما فقط میدانید که SLA شکسته شده، اما نمیدانید چرا و چگونه.
تیمهای SRE از دادههای Observability برای تصمیمگیری خودکار استفاده میکنند — مثلاً اگر latency از حد مجاز بالاتر برود، یک اسکریپت Auto-Scale اجرا شود.
معماری فنی Observability Stack
یک معماری استاندارد Observability معمولاً شامل این اجزا است:
[Applications & Nodes]
↓
[Exporters & Agents]
↓
[Data Collection Layer (Prometheus, Loki, Tempo)]
↓
[Storage (Time-Series DBs, Object Storage)]
↓
[Visualization (Grafana)]
↓
[Alerting & Automation]
در این معماری، Prometheus دادههای متریک را جمعآوری میکند، Loki لاگها را ذخیره میکند و Tempo مسئول Traces است.
Grafana دادهها را در یک UI واحد نمایش میدهد تا بتوانید ارتباط بین متریک، لاگ و Trace را ببینید.
به این ترکیب معمولاً Observability Stack گفته میشود.
Observability در محیطهای Cloud و Container
در سیستمهای Cloud Native، سرویسها دائم ساخته و حذف میشوند.
مانیتورینگ سنتی برای چنین محیطی طراحی نشده، چون فرض میکند منابع ثابت هستند.
اما در Kubernetes یا Docker، هر container میتواند عمر چند دقیقهای داشته باشد.
Observability در این فضا با ابزارهایی مثل Prometheus Operator، Grafana Loki و Tempo اجرا میشود.
با کمک OpenTelemetry، دادهها از تمام Podها، Serviceها و Nodeها جمعآوری شده و در یک پایگاه واحد تحلیل میشوند.
در نتیجه، حتی اگر یک container حذف شود، دادههایش باقی میمانند.
بهعنوان مثال، اگر latency در سرویس API افزایش یابد، با Trace میتوان فهمید آیا مشکل از شبکه است، از دیتابیس یا از کد.
Observability و هوش مصنوعی (AIOps)
حجم دادههای Observability معمولاً بسیار زیاد است. تحلیل دستی آنها برای تیمهای بزرگ هم دشوار است.
در اینجا AIOps (Artificial Intelligence for IT Operations) وارد عمل میشود.
مدلهای یادگیری ماشین و هوش مصنوعی میتوانند با بررسی روندها و الگوها، ناهنجاریها را شناسایی کنند.
برای مثال، اگر نرخ خطا معمولاً ۱٪ باشد و ناگهان به ۳٪ برسد، سیستم هشدار هوشمند میدهد.
حتی ChatGPT یا مدلهای LLM میتوانند به تحلیل لاگها کمک کنند:
- دستهبندی خطاها بر اساس نوع و شدت
- خلاصهسازی گزارشها
- پیشنهاد خودکار برای رفع مشکل
نوینهاست از همین ایدهها در سیستمهای مانیتورینگ خود استفاده میکند تا مشکلات قبل از تأثیرگذاری بر کاربران شناسایی شوند.
مزایای Observability برای مدیران سرور
۱. دید ۳۶۰ درجه از سیستم
بهجای نگاه جزیرهای به سرور، شما یک تصویر کامل از زیرساخت دارید — از پردازنده تا پایگاه داده.
۲. کاهش زمان تشخیص خطا (MTTR)
یافتن علت اصلی خطا بهجای حدس و آزمایش.
۳. بهبود پایداری (Stability)
Observability کمک میکند سیستم قبل از خرابی هشدار دهد.
۴. تصمیمگیری مبتنی بر داده (Data-Driven)
بهجای “احساس”، با شواهد واقعی تصمیم بگیرید.
۵. خودکارسازی واکنشها (Automation)
با ترکیب Observability و ابزارهایی مثل Ansible یا ChatGPT API میتوان Auto-Remediation پیادهسازی کرد.
چالشها و اشتباهات رایج
Observability فقط ابزار نیست، یک فرهنگ کاری است.
- جمعآوری بیهدف دادهها: داده زیاد بدون تحلیل، فقط هزینه و سردرگمی میآورد.
- Alert Fatigue: هشدارهای بیربط باعث میشوند هشدارهای مهم نادیده گرفته شوند.
- نبود استاندارد نامگذاری: اگر متریکها یا لاگها ساختار یکسان نداشته باشند، همبستگی بینشان سخت میشود.
- فقدان آموزش تیمها: اگر اعضا ندانند با دادهها چه کنند، Observability عملاً بیاثر است.
نقشه راه پیادهسازی Observability در سازمانها
جمعآوری دادهها
با نصب Prometheus و Loki شروع کنید و Exporterها را روی سرورها فعال کنید.
تجسم دادهها
Grafana را راهاندازی کنید و داشبوردهای شخصیسازیشده بسازید.
همبستگی و تحلیل علتها
دادههای Metrics، Logs و Traces را در Grafana به هم لینک کنید.
خودکارسازی و یادگیری
از ابزارهای AIOps یا ChatGPT برای تحلیل خودکار لاگها استفاده کنید و سیستم را به نقطهی Self-Healing برسانید.
مثال واقعی از کاربرد Observability
فرض کنید در سرور فروشگاه اینترنتی شما کاربران از کندی checkout شکایت دارند.
- در مانیتورینگ سنتی فقط میدانید CPU روی ۹۰٪ است.
- اما با Observability، با بررسی Trace مشخص میشود که bottleneck در query مربوط به جدول orders است.
- سپس با بررسی لاگها متوجه میشوید بعد از انتشار نسخه جدید API، query جدیدی اضافه شده که index ندارد.
با یک نگاه ترکیبی، علت اصلی در چند دقیقه پیدا میشود.
Observability در زیرساخت نوین هاست
در نوین هاست ما از Observability نه بهعنوان شعار، بلکه بهعنوان بخشی از طراحی زیرساخت استفاده میکنیم.
تمام سرورهای ابری و اختصاصی نوینهاست به سیستم مانیتورینگ ترکیبی مجهزند که شامل:
- Prometheus برای جمعآوری دادهها
- Grafana برای تحلیل و Visualization
- Loki برای مدیریت لاگها
- Alertmanager برای هشدارهای هوشمند
این ترکیب باعث میشود تیم فنی ما قبل از بروز خطا، آن را پیشبینی و اصلاح کند.
به همین دلیل است که سرورهای نوینهاست به پایداری واقعی (High Reliability) معروفاند.
آینده Observability؛ از تحلیل تا خودترمیمی
نسل بعدی Observability به سمت Self-Healing Infrastructure حرکت میکند — زیرساختی که خودش مشکل را تشخیص میدهد و خودش رفع میکند.
با ترکیب Observability، AIOps و ChatGPT، سرور میتواند رفتار غیرعادی را تشخیص دهد، علت را تحلیل کند و مثلاً سرویس مربوطه را ریستارت نماید.
این آینده، نزدیکتر از چیزی است که فکر میکنید.
جمعبندی
مانیتورینگ، دیدن است؛ Observability، درک کردن.
در دنیای چندلایهی امروز، تنها با جمعآوری داده نمیتوان مشکلات را حل کرد.
Observability به شما کمک میکند از انبوه دادهها، بینش بسازید — بینشی که به معنای پایداری، سرعت و اعتماد است.
با ابزارهایی مانند Prometheus، Grafana، Loki و Tempo میتوانید زیرساختی شفاف، سریع و هوشمند بسازید که همیشه یک قدم جلوتر از بحران است.
نوین هاست یار نوین شماست
در نوین هاست، ما معتقدیم هر سرور باید دیده شود، درک شود و قبل از بروز خطا واکنش نشان دهد.
با بهرهگیری از فناوریهای Observability و ابزارهای متنباز مانند Grafana، Prometheus و هوش مصنوعی، سرورهای نوینهاست همیشه در بالاترین سطح عملکرد و شفافیت کار میکنند.
اگر بهدنبال زیرساختی هستید که نهتنها سریع و امن، بلکه هوشمند و پیشبین باشد، نوین هاست یار نوین شماست