

چرا ترمیم خودکار دیگر یک انتخاب نیست
زیرساختهای دیجیتال امروزی در محیطی فعالیت میکنند که پایداری بهتنهایی کافی نیست. کاربران انتظار دارند سرویسها همیشه در دسترس باشند، حتی زمانی که اجزای داخلی سیستم دچار اختلال میشوند. در چنین فضایی، واکنش انسانی به خطا دیگر پاسخگو نیست. سرعت رخدادها بالاست و وابستگی سرویسها به یکدیگر پیچیدهتر از گذشته شده است.
در گذشته، تیمهای فنی با مانیتورینگ سنتی و هشدارهای دستی به خطا پاسخ میدادند. اما امروزه همین رویکرد باعث تاخیر در واکنش، افزایش Downtime و در نهایت آسیب به تجربه کاربر میشود. Self-Healing Systems پاسخی به همین تغییر بنیادین هستند؛ سامانههایی که بهجای انتظار برای دخالت انسان، خودشان وضعیت را تشخیص میدهند و مسیر ترمیم را اجرا میکنند.
Self-Healing System دقیقا چیست؟
به معماریای گفته میشود که قادر است سلامت خود را بهطور مداوم ارزیابی کند. این سیستم ابتدا رفتار نرمال را میشناسد و آن را بهعنوان مبنا در نظر میگیرد. سپس هرگونه انحراف از این وضعیت پایدار را شناسایی میکند.
نکته کلیدی اینجاست که Self-Healing صرفا یک واکنش ساده نیست. سیستم بعد از تشخیص خطا، تلاش میکند بهترین اقدام اصلاحی را انتخاب کند. این اقدام ممکن است بسیار ساده باشد، مانند ریست یک سرویس، یا بسیار پیچیده، مانند جابهجایی بار کاری بین چند دیتاسنتر. هدف نهایی همیشه یک چیز است؛ بازگرداندن سرویس به حالت سالم، بدون ایجاد اختلال محسوس برای کاربر.
چرا High Availability بهتنهایی کافی نیست
High Availability با ایجاد افزونگی تلاش میکند احتمال قطعی را کاهش دهد. این رویکرد در بسیاری از سناریوها مفید است، اما محدودیت دارد. HA فرض میکند که خرابی یک اتفاق نادر است و باید با نسخه پشتیبان جبران شود.
Self-Healing نگاه متفاوتی دارد. این رویکرد خطا را بخشی طبیعی از سیستم میداند. بهجای تمرکز صرف بر جلوگیری از خرابی، بر مدیریت هوشمند آن تمرکز میکند. در نتیجه، سیستم نهتنها قطعی را کاهش میدهد، بلکه حتی در صورت بروز خطا، تاثیر آن را به حداقل میرساند.
معماری ذهنی Self-Healing؛ از تشخیص تا ترمیم
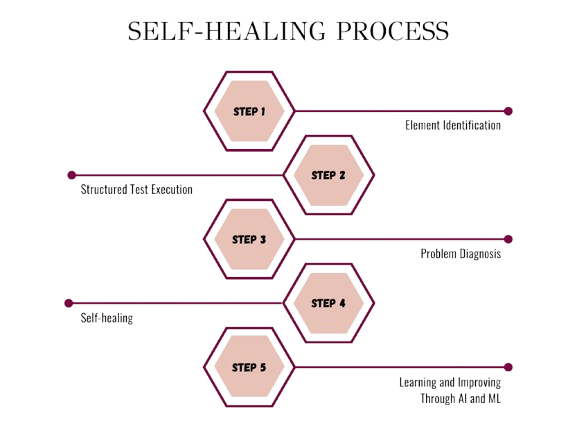
هر سیستم خودترمیم یک چرخه مشخص دارد. این چرخه معمولا با تشخیص آغاز میشود. در این مرحله، سیستم با استفاده از متریکها، لاگها و رویدادها نشانههای غیرعادی را شناسایی میکند.
پس از تشخیص، مرحله تحلیل آغاز میشود. سیستم تلاش میکند بفهمد اختلال از کجا نشات گرفته است. آیا مشکل از کمبود منابع است یا یک سرویس خاص پاسخگو نیست؟
در مرحله بعد، سیستم تصمیم میگیرد. این تصمیم میتواند شامل افزایش منابع، جابهجایی سرویس، تغییر مسیر ترافیک یا حتی ایزولهکردن یک نود باشد.
در نهایت، سیستم اقدام را اجرا میکند و نتیجه را دوباره ارزیابی میکند. این چرخه بهصورت مداوم تکرار میشود و به سیستم امکان یادگیری میدهد.
Observability؛ ستون فقرات Self-Healing
بدون Observability، Self-Healing عملا غیرممکن است. سیستم باید بتواند وضعیت داخلی خود را با دقت بالا ببیند. متریکهایی مانند CPU، RAM، Latency و Error Rate تنها نقطه شروع هستند.
در معماریهای توزیعشده، Distributed Tracing اهمیت زیادی دارد. این ابزار کمک میکند مسیر یک درخواست در میان چندین سرویس ردیابی شود. وقتی یک خطا رخ میدهد، سیستم میتواند بفهمد کدام بخش زنجیره عامل اصلی بوده است.
هرچه Observability عمیقتر باشد، تصمیمهای ترمیمی دقیقتر و کمریسکتر خواهند بود.
Self-Healing در سطح سیستمعامل
در لایه سیستمعامل، Self-Healing معمولا با پایش فرآیندها آغاز میشود. اگر یک سرویس دچار Memory Leak شود یا بهطور غیرعادی CPU مصرف کند، سیستم میتواند آن را شناسایی کند.
در چنین شرایطی، بهجای منتظر ماندن برای Crash کامل، سیستم سرویس را بازنشانی میکند یا آن را به نمونه سالم دیگری منتقل میکند. این رفتار از گسترش اختلال جلوگیری میکند و پایداری کلی سرور را حفظ میکند.
Self-Healing در Kubernetes و کانتینرها
Kubernetes یکی از ملموسترین نمونههای Self-Healing در دنیای واقعی است. وقتی یک Pod از کار میافتد، سیستم بهطور خودکار Pod جدید ایجاد میکند. اگر یک Node ناپایدار شود، بار کاری به Nodeهای سالم منتقل میشود.
Liveness Probe و Readiness Probe به Kubernetes کمک میکنند وضعیت واقعی سرویس را تشخیص دهد. این ابزارها باعث میشوند خطا پیش از آنکه به کاربر برسد، اصلاح شود.
Self-Healing در لایه شبکه
در لایه شبکه، Self-Healing بهمعنای مدیریت هوشمند مسیرهاست. اگر یک لینک دچار Packet Loss شود، سیستم میتواند مسیر جایگزین را فعال کند.
ترکیب Self-Healing با Anycast و Smart Routing باعث میشود کاربر همیشه از پایدارترین مسیر استفاده کند. این رویکرد نقش مهمی در کاهش Latency و افزایش کیفیت سرویس دارد.
نقش هوش مصنوعی در Self-Healing
هوش مصنوعی Self-Healing را از یک سیستم مبتنیبر Rule به یک سیستم یادگیرنده تبدیل میکند. Machine Learning میتواند الگوهای خرابی را قبل از وقوع بحران شناسایی کند.
Reinforcement Learning به سیستم اجازه میدهد از نتایج تصمیمهای قبلی درس بگیرد. اگر یک اقدام اصلاحی نتیجه خوبی نداشته باشد، سیستم در آینده آن را اصلاح میکند. این همان نقطهای است که Self-Healing به Reflexive Infrastructure نزدیک میشود.
مثال عملی؛ فروشگاه آنلاین پرترافیک
فرض کنید یک فروشگاه آنلاین در زمان کمپین تبلیغاتی با افزایش ناگهانی ترافیک مواجه میشود. سیستم Self-Healing افزایش Latency را تشخیص میدهد و متوجه میشود یک سرویس خاص به گلوگاه تبدیل شده است.
سیستم بدون دخالت انسان، نمونههای جدیدی از آن سرویس ایجاد میکند و Load Balancer ترافیک را بین آنها توزیع میکند. کاربر افت کیفیت را احساس نمیکند و فروش ادامه پیدا میکند.
Self-Healing و امنیت
Self-Healing تنها برای پایداری نیست. این رویکرد نقش مهمی در امنیت دارد. سیستم میتواند رفتار غیرعادی را شناسایی کند و نود مشکوک را ایزوله کند.
در حملات DDoS، Self-Healing میتواند نرخ درخواستها را محدود کند یا ترافیک را به مسیرهای امن هدایت کند. این واکنش سریع، تاثیر حمله را به حداقل میرساند.
چالشهای پیادهسازی
Self-Healing معماری سادهای ندارد. طراحی اشتباه میتواند باعث تصمیمهای نادرست شود. هزینه پردازش و پیچیدگی هماهنگی اجزا از چالشهای اصلی هستند.
به همین دلیل، پیادهسازی موفق نیازمند تست مداوم، مانیتورینگ دقیق و طراحی مرحلهای است.
آینده Self-Healing Systems
Self-Healing یکی از پایههای Autonomous Infrastructure است. در آینده، زیرساختها نهتنها خطا را ترمیم میکنند، بلکه مصرف انرژی، هزینه و تجربه کاربر را نیز بهینه میکنند.
در این مسیر، نقش تیمهای فنی از واکنش به طراحی سیاستهای هوشمند تغییر خواهد کرد.
جمعبندی
Self-Healing Systems پاسخی مستقیم به پیچیدگی زیرساختهای مدرن هستند. این سامانهها با ترکیب Observability، اتوماسیون و هوش مصنوعی، پایداری واقعی را ممکن میکنند.
کسبوکارهایی که به آینده فکر میکنند، بدون Self-Healing نمیتوانند زیرساختی قابل اعتماد و مقیاسپذیر بسازند.
نوین هاست یار نوین شماست
تیم فنی نوین هاست با پایش مداوم سرویسها و واکنش هوشمندانه به اختلالها، پایداری و کیفیت را در اولویت قرار میدهد. اگر بهدنبال میزبانی حرفهای و همسو با آینده زیرساختهای هوشمند هستید، نوین هاست انتخابی مطمئن برای کسبوکار شماست.





