هیچ زیرساختی مصون از خطا نیست. خرابی سختافزار، خطای انسانی، حمله سایبری، باجافزار، قطع برق گسترده یا حتی یک اشتباه در بهروزرسانی نرمافزار میتواند سرویس یک سازمان را متوقف کند. در دنیایی که کسبوکارها به صورت ۲۴ ساعته فعالیت میکنند، توقف چند ساعته میتواند خسارت مالی و اعتباری جدی ایجاد کند. در چنین شرایطی سازمانها نمیتوانند فقط به Backup اکتفا کنند. آنها به یک استراتژی کامل Disaster Recovery نیاز دارند.
Disaster Recovery یا DR مجموعهای از فرآیندها، معماریها و ابزارهاست که سازمان طراحی میکند تا پس از وقوع یک بحران، سرویسهای حیاتی را در کوتاهترین زمان ممکن بازیابی کند. DR فقط تهیه نسخه پشتیبان نیست؛ بلکه یک استراتژی عملیاتی برای بازگرداندن کسبوکار به وضعیت پایدار است.
تفاوت Backup و Disaster Recovery
بسیاری از سازمانها Backup را با DR اشتباه میگیرند. Backup فقط نسخهای از دادهها ایجاد میکند. اگر سرور از کار بیفتد، تیم فنی باید زیرساخت جدید ایجاد کند، سیستمعامل نصب کند، اپلیکیشنها را پیکربندی کند و سپس دادهها را بازیابی کند. این فرآیند ممکن است ساعتها یا حتی روزها طول بکشد.
Disaster Recovery فراتر از Backup عمل میکند. در یک استراتژی DR، سازمان نهتنها از دادهها نسخه پشتیبان میگیرد، بلکه زیرساخت جایگزین، فرآیند بازیابی، سناریوهای بحران و نقشهای عملیاتی را از قبل مشخص میکند. هدف DR این است که وقفه سرویس را به حداقل برساند و کسبوکار را در سریعترین زمان ممکن به وضعیت عملیاتی بازگرداند.
RPO و RTO؛ دو شاخص حیاتی در طراحی DR
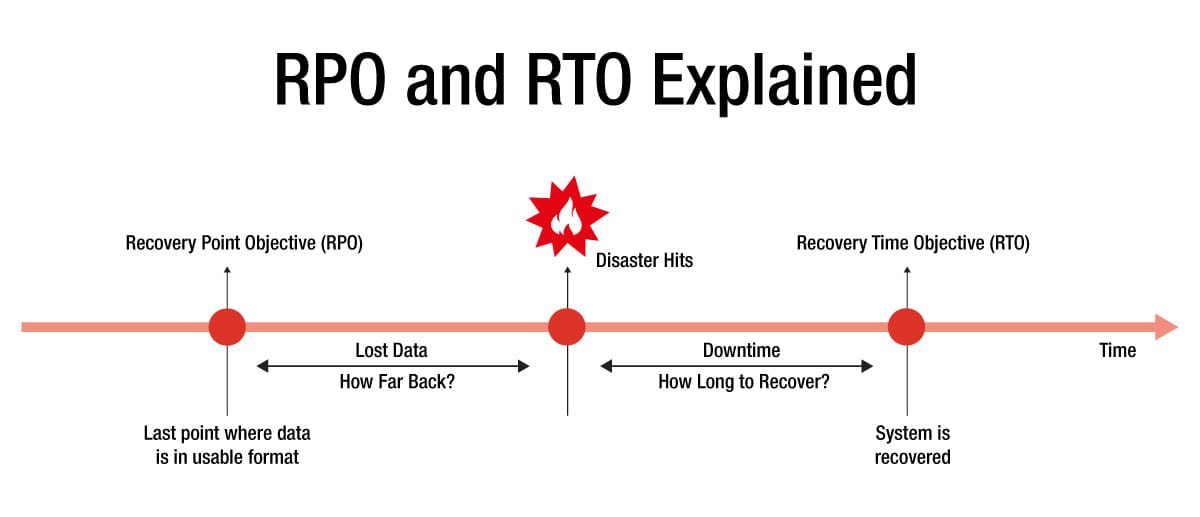
هر استراتژی DR بر دو شاخص کلیدی استوار است: RPO و RTO. سازمان باید پیش از هر تصمیم معماری، این دو مقدار را تعریف کند.
RPO یا Recovery Point Objective مشخص میکند حداکثر چه میزان از داده قابل از دست رفتن است. اگر RPO برابر با ۱۵ دقیقه باشد، سازمان میپذیرد که در بدترین حالت ۱۵ دقیقه از دادهها از بین برود. هرچه RPO کوچکتر باشد، سازمان باید از Replication لحظهای یا نزدیک به لحظه استفاده کند.
RTO یا Recovery Time Objective مدت زمانی است که سازمان میتواند سرویس را متوقف نگه دارد. اگر RTO برابر با یک ساعت باشد، تیم فنی باید ظرف یک ساعت سرویس را بازیابی کند. کاهش RTO نیازمند زیرساخت آماده و خودکارسازی فرآیند بازیابی است.
بدون تعریف دقیق RPO و RTO، طراحی DR فاقد هدف مشخص خواهد بود.
انواع سناریوهای Disaster که باید در نظر بگیریم
سازمانها نباید فقط به یک نوع بحران فکر کنند. DR واقعی باید چندین سناریو را پوشش دهد.
خرابی سختافزاری یکی از رایجترین سناریوهاست. خرابی دیسک، سرور یا تجهیزات شبکه میتواند سرویس را مختل کند. در این حالت معماری High Availability میتواند نقش مهمی ایفا کند.
خطای انسانی نیز خطر بزرگی محسوب میشود. حذف اشتباهی دیتابیس یا اعمال تنظیمات اشتباه میتواند سیستم را از کار بیندازد. DR باید امکان بازگرداندن وضعیت قبلی را فراهم کند.
حملات سایبری بهویژه باجافزارها یکی از تهدیدهای جدی امروز هستند. اگر مهاجم دادهها را رمزگذاری کند، سازمان باید نسخهای ایزوله و غیرقابل دسترس برای مهاجم در اختیار داشته باشد.
حوادث طبیعی مانند آتشسوزی یا سیل میتوانند یک دیتاسنتر کامل را از کار بیندازند. در این شرایط فقط یک سایت جایگزین جغرافیایی میتواند سرویس را نجات دهد.
معماریهای مختلف Disaster Recovery
سازمانها بسته به حساسیت سرویس و بودجه خود میتوانند از معماریهای مختلف DR استفاده کنند.
در مدل Cold Standby سازمان فقط نسخه پشتیبان دادهها را در یک سایت دیگر نگهداری میکند. در زمان بحران تیم فنی زیرساخت را راهاندازی و دادهها را بازیابی میکند. این مدل هزینه کمتری دارد اما RTO بالاتری ایجاد میکند.
در مدل Warm Standby سازمان یک زیرساخت آماده اما با ظرفیت محدود در سایت دوم نگه میدارد. در صورت وقوع بحران، سیستم اصلی به سایت دوم منتقل میشود و منابع افزایش مییابد. این مدل تعادل میان هزینه و سرعت بازیابی ایجاد میکند.
در معماری Active-Passive سایت اصلی فعال است و سایت دوم آماده دریافت بار است. دادهها به صورت مداوم Replicate میشوند. هنگام بروز مشکل، ترافیک به سایت دوم منتقل میشود.
در مدل Active-Active هر دو سایت همزمان فعال هستند و بار میان آنها توزیع میشود. اگر یکی از سایتها از کار بیفتد، سایت دیگر به صورت کامل بار را تحمل میکند. این مدل پایینترین RTO را ارائه میدهد اما هزینه و پیچیدگی بیشتری دارد.
Replication در سطح Storage یا Application
یکی از تصمیمهای مهم در طراحی DR انتخاب سطح Replication است. در Replication مبتنی بر Storage، سیستم ذخیرهسازی دادهها را به صورت بلاکمحور به سایت دوم منتقل میکند. این روش ساده و سریع است اما وابستگی زیادی به زیرساخت Storage دارد.
در Replication سطح Application، خود نرمافزار یا دیتابیس دادهها را همگامسازی میکند. این روش کنترل بیشتری ارائه میدهد و انعطافپذیرتر است اما نیاز به تنظیمات دقیقتری دارد.
سازمان باید با توجه به نوع Workload، حساسیت داده و معماری نرمافزار، مناسبترین روش را انتخاب کند.
نقش Cloud در Disaster Recovery
Cloud امکان پیادهسازی DR با هزینه کمتر و انعطاف بیشتر را فراهم میکند. سازمان میتواند سایت DR را در یک Cloud عمومی یا خصوصی راهاندازی کند و تنها در زمان نیاز منابع را فعال کند.
Cloud به سازمان اجازه میدهد بدون خرید سختافزار اضافی، زیرساخت جایگزین ایجاد کند. همچنین بسیاری از ارائهدهندگان Cloud ابزارهای Replication و Snapshot پیشرفته ارائه میدهند که فرآیند DR را سادهتر میکنند.
با این حال سازمان باید به Latency، پهنای باند و قوانین اقامت داده توجه کند تا در زمان بحران با محدودیت مواجه نشود.
DR در دیتاسنتر اختصاصی
سازمانهایی که دیتاسنتر اختصاصی دارند میتوانند سایت DR را در یک موقعیت جغرافیایی دیگر ایجاد کنند. این سایت باید از نظر برق، شبکه و امنیت فیزیکی مستقل باشد تا یک حادثه مشترک هر دو سایت را تحت تاثیر قرار ندهد.
اتصال میان دو سایت باید پایدار و پرسرعت باشد تا Replication بدون وقفه انجام شود. همچنین تیم فنی باید فرآیند Failover و Failback را مستند و خودکارسازی کند.
اهمیت تست دورهای Disaster Recovery
بسیاری از سازمانها استراتژی DR طراحی میکنند اما آن را تست نمیکنند. DR بدون تست عملی فقط یک سند روی کاغذ است. تیم فنی باید سناریوهای مختلف را شبیهسازی کند و عملکرد سیستم را در شرایط واقعی بررسی کند.
تست دورهای به سازمان کمک میکند نقاط ضعف را شناسایی کند، زمان بازیابی را اندازهگیری کند و فرآیندها را بهبود دهد. بدون این تستها، در زمان بحران واقعی احتمال خطا افزایش پیدا میکند.
اشتباهات رایج در طراحی DR
یکی از اشتباهات رایج تمرکز صرف بر Backup است. سازمان تصور میکند داشتن نسخه پشتیبان کافی است در حالی که بدون زیرساخت آماده، بازیابی زمانبر خواهد بود.
اشتباه دیگر عدم توجه به سناریوهای انسانی است. بسیاری از بحرانها ناشی از خطای داخلی هستند و سازمان باید مکانیزمهای کنترلی و لاگبرداری دقیق داشته باشد.
برخی سازمانها نیز RPO و RTO غیرواقعی تعیین میکنند. اگر بودجه و زیرساخت متناسب با این اهداف نباشد، استراتژی DR در عمل شکست خواهد خورد.
سناریوی عملی طراحی DR برای یک سازمان متوسط
فرض کنید یک شرکت تجارت الکترونیک با هزاران کاربر روزانه فعالیت میکند. این شرکت نمیتواند بیش از ۳۰ دقیقه قطعی را تحمل کند و حداکثر ۵ دقیقه از دست رفتن داده را میپذیرد. بنابراین RTO برابر با ۳۰ دقیقه و RPO برابر با ۵ دقیقه تعریف میشود.
برای رسیدن به این اهداف، شرکت یک معماری Active-Passive در دو دیتاسنتر مجزا طراحی میکند. دیتابیس به صورت نزدیک به لحظه Replicate میشود و سیستم Load Balancer امکان تغییر مسیر ترافیک را فراهم میکند. تیم فنی هر سه ماه یک بار سناریوی Failover را تست میکند و زمان بازیابی را اندازهگیری میکند.
این رویکرد باعث میشود در صورت بروز بحران، شرکت بتواند در کمتر از نیم ساعت سرویس را بازیابی کند و حداقل داده از دست برود.
جمعبندی نهایی
Disaster Recovery یک انتخاب لوکس نیست بلکه بخشی حیاتی از معماری زیرساخت محسوب میشود. سازمانی که فقط به Backup تکیه کند در زمان بحران با چالش جدی مواجه خواهد شد. طراحی یک استراتژی واقعی DR نیازمند تعریف دقیق RPO و RTO، انتخاب معماری مناسب، پیادهسازی Replication مؤثر و تست دورهای است.
سازمانهایی که DR را به صورت عملی و نه صرفاً نظری پیادهسازی میکنند میتوانند ریسک عملیاتی را کاهش دهند، اعتماد مشتریان را حفظ کنند و در برابر بحرانها پایدار بمانند.
نوین هاست یار نوین شماست
نوین هاست با طراحی زیرساختهای پایدار و ارائه راهکارهای Disaster Recovery متناسب با نیاز هر سازمان، امکان بازیابی سریع سرویسها را فراهم میکند. تیم تخصصی نوین هاست معماری DR را بر اساس RPO و RTO واقعی کسبوکار شما طراحی میکند و زیرساختی مقاوم در برابر بحران ایجاد مینماید. اگر به دنبال زیرساختی هستید که در شرایط بحرانی نیز پایدار بماند، نوین هاست یار نوین شماست.