

در عصر زیرساختهای توزیعشده، میکروسرویسها و معماریهای ابری، پایداری سیستمها دیگر صرفاً حاصل سختافزار قدرتمند یا افزونگی نیست.
در این ساختارها، اجزای متعدد نرمافزاری و شبکهای بهصورت پویا در تعامل هستند و بروز اختلال در هر بخش میتواند بر کل سرویس اثر بگذارد.
به همین دلیل، مفهوم تابآوری سیستمها (System Resilience) و روشهای ارزیابی آن به مسئلهای اساسی در مهندسی زیرساخت تبدیل شده است.
یکی از رویکردهای پیشرو در این زمینه، Chaos Engineering (مهندسی هرجومرج) است.
در این روش، مهندسان بهصورت آگاهانه و کنترلشده در سیستم اختلال ایجاد میکنند تا رفتار آن را در شرایط غیرعادی مشاهده کرده و نقاط ضعف پنهان را شناسایی نمایند.
Chaos Engineering برخلاف تستهای سنتی که در محیطهای ایزوله انجام میشوند، بهصورت زنده و بر روی سیستمهای واقعی اجرا میشود تا واکنش طبیعی زیرساخت در برابر خطا مشخص گردد.
این مقاله به بررسی مفهوم، فلسفه، مراحل اجرایی، ابزارها و کاربردهای Chaos Engineering در زیرساختهای مدرن میپردازد و نشان میدهد چگونه این رویکرد، پایداری واقعی سرورها و خدمات ابری را تضمین میکند.
تعریف Chaos Engineering
Chaos Engineering شاخهای از مهندسی سیستم است که با هدف افزایش تابآوری،
اختلالات کنترلشدهای را در محیطهای واقعی اعمال میکند تا رفتار سیستم در مواجهه با خطاهای غیرمنتظره بررسی شود.
بهعبارت دقیقتر، Chaos Engineering علمی است که میکوشد از طریق آزمایش تجربی اختلالها در سیستمهای توزیعشده،
درک عمیقتری از عملکرد واقعی آنها در زمان بحران بهدست آورد.
در این چارچوب، هر آزمایش «فرضیهای» را مورد بررسی قرار میدهد؛ برای مثال:
«در صورت از کار افتادن یکی از گرههای پایگاه داده، سیستم باید بدون اختلال برای کاربران نهایی به کار خود ادامه دهد.»
اگر سیستم مطابق این فرضیه رفتار کند، به معنای وجود مقاومت کافی است؛ در غیر این صورت، نقص طراحی یا پیکربندی شناسایی و مستند میشود.
Chaos Engineering برخلاف تستهای سنتی (مانند Load Test یا Stress Test) بر رفتار واقعی سیستم در برابر شکست (Failure Behavior) تمرکز دارد، نه صرفاً عملکرد در بار بالا.
فلسفه و تاریخچه Chaos Engineering
مفهوم Chaos Engineering نخستینبار در سال ۲۰۱۰ در شرکت Netflix شکل گرفت.
Netflix در آن زمان میلیونها کاربر در سراسر جهان داشت و تمامی سرویسهایش بر بستر AWS Cloud اجرا میشدند.
در چنین محیطی، حتی خرابی یک ماشین مجازی یا قطعی یک Availability Zone میتوانست تجربه میلیونها کاربر را مختل کند.
برای اطمینان از تابآوری زیرساخت، تیم مهندسی Netflix ابزاری به نام Chaos Monkey ایجاد کرد.
این ابزار بهصورت تصادفی، برخی از سرورها را خاموش میکرد تا واکنش سرویس در برابر از دست رفتن منابع بررسی شود.
نتیجه این آزمایشها بهبود قابلتوجهی در طراحی معماری توزیعشده Netflix به همراه داشت.
در ادامه، این ایده گسترش یافت و مجموعهای از ابزارها با نام Simian Army توسعه داده شد
که انواع اختلالات از قبیل قطعی شبکه، خرابی دیسک یا تاخیر در پاسخگویی را شبیهسازی میکردند.
در سطح فلسفی، Chaos Engineering بر این اصل استوار است که:
«سیستمهای پیچیده بهطور طبیعی مستعد شکست هستند، و بهترین راه برای مقابله با شکست، یادگیری از آن پیش از وقوع واقعی است.»
اهداف و اهمیت Chaos Engineering
هدف اصلی Chaos Engineering ایجاد اعتماد به عملکرد سیستم در شرایط نامطلوب است.
با اجرای آزمایشهای هرجومرج، تیمهای DevOps میتوانند ضعفهای طراحی، تنظیمات نادرست و نقاط شکست را قبل از بروز بحران واقعی شناسایی و رفع کنند.
اهمیت این روش در چند بعد قابل تحلیل است:
- پایداری (Stability):
سیستم باید در برابر خرابی اجزای جزئی، پایداری کلی خود را حفظ کند. - تابآوری (Resilience):
پس از وقوع خطا، سیستم باید توانایی بازیابی سریع خود را داشته باشد. - قابلیت مشاهده (Observability):
آزمایشهای Chaos به توسعهدهندگان کمک میکند تا درک بهتری از جریان داده و وابستگیهای درونی سرویسها پیدا کنند. - فرهنگ مهندسی پیشفعال (Proactive Engineering):
بهجای واکنش به خطا پس از وقوع، تیمها خطا را پیشبینی و مدیریت میکنند.
چارچوب اجرای Chaos Engineering
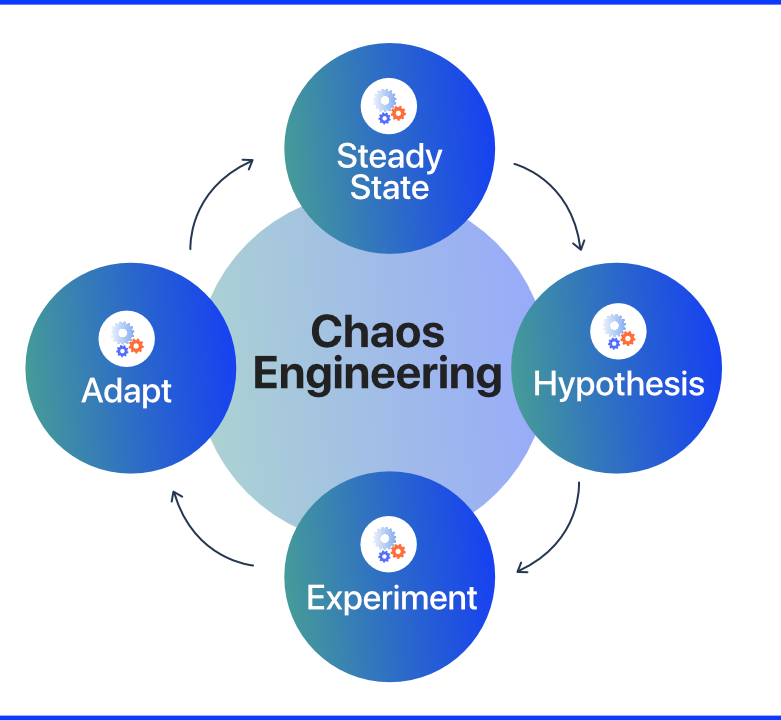
Chaos Engineering فرآیندی نظاممند است و بر اساس مدل علمی «فرضیه و آزمون» اجرا میشود.
این چارچوب معمولاً شامل مراحل زیر است:
۱. تعریف وضعیت پایدار (Steady State)
در گام نخست، باید رفتار عادی سیستم مشخص شود.
برای مثال، نرخ پاسخ موفق API، میانگین تأخیر (Latency) یا نرخ خطای مجاز.
این وضعیت مرجع مقایسه در مراحل بعدی خواهد بود.
۲. تدوین فرضیه (Form Hypothesis)
فرضیه مشخص میکند که در صورت وقوع یک اختلال خاص، انتظار داریم سیستم چه واکنشی نشان دهد.
نمونه:
«اگر یکی از سرورهای وب از دسترس خارج شود، Load Balancer باید ترافیک را به سرورهای باقیمانده هدایت کند.»
۳. اجرای اختلال کنترلشده (Inject Chaos)
در این مرحله، آزمایش واقعی اجرا میشود.
نوع اختلال میتواند شامل خاموش کردن یک گره، کاهش پهنای باند شبکه، افزایش تاخیر یا خرابی پایگاه داده باشد.
۴. مشاهده و اندازهگیری نتایج (Observe & Measure)
رفتار سیستم در برابر اختلال بررسی و دادهها جمعآوری میشود.
در این مرحله، ابزارهای مانیتورینگ مانند Prometheus یا Grafana نقش کلیدی دارند.
۵. تحلیل و یادگیری (Learn & Improve)
در نهایت، نتایج آزمایش تحلیل و نقاط ضعف شناسایی میشود.
سپس تغییرات لازم در طراحی، تنظیمات یا سیاستهای بازیابی اعمال میگردد.
این چرخه بهصورت مستمر تکرار میشود تا سیستم بهمرور مقاومتر شود.
ابزارهای Chaos Engineering
ابزارهای متنوعی برای اجرای Chaos Engineering در محیطهای مختلف توسعه یافتهاند.
| ابزار | توضیح | محیط کاربرد |
|---|---|---|
| Chaos Monkey | ابزار کلاسیک Netflix برای خاموشکردن تصادفی سرورها | Cloud (AWS) |
| Gremlin | پلتفرم تجاری با رابط کاربری گرافیکی و گزارش تحلیلی | Multi-Cloud |
| Chaos Mesh | پروژه متنباز از CNCF برای Kubernetes | Container / K8s |
| LitmusChaos | چارچوب Cloud Native برای اجرای سناریوهای Chaos در Kubernetes | DevOps Pipeline |
| PowerfulSeal | ابزار مناسب برای تست هرجومرج در ماشینهای مجازی | Private Cloud / OpenStack |
انتخاب ابزار به نوع زیرساخت (VM، Container یا Cloud Native) و سطح کنترل تیم بستگی دارد.
تفاوت Chaos Engineering با آزمونهای عملکردی سنتی
Chaos Engineering نباید با تستهای عملکردی کلاسیک اشتباه گرفته شود.
در جدول زیر تفاوت اصلی این رویکرد با Load Testing مشخص شده است:
| ویژگی | Load Test | Chaos Engineering |
|---|---|---|
| هدف | بررسی عملکرد در بار بالا | بررسی رفتار در شرایط خطا |
| نوع اختلال | فشار بر منابع | ایجاد خرابی واقعی |
| نتیجه مورد انتظار | اطمینان از کارایی | اطمینان از پایداری |
| زمان اجرا | پیش از انتشار نسخه | در محیط زنده (Production) |
| تمرکز اصلی | ظرفیت و سرعت | تابآوری و خودبازیابی |
به بیان دیگر، Load Test پاسخ سیستم در برابر «بار زیاد» را میسنجد،
در حالی که Chaos Engineering پاسخ سیستم در برابر «خرابی» را تحلیل میکند.
اجرای Chaos Engineering در محیطهای ابری و هاستینگ
در شرکتهای هاستینگ و Cloud Providerها،
اجرای Chaos Engineering اهمیت مضاعفی دارد؛ زیرا پایداری مستقیم بر تجربهی مشتری اثر میگذارد.
نمونههایی از آزمایشهای قابلاجرا در محیطهای هاستینگ:
- قطع موقت یکی از Nodeهای ذخیرهسازی (Storage Node) و بررسی رفتار Replicaها
- ایجاد تأخیر در شبکه بین دو دیتاسنتر و ارزیابی عملکرد Load Balancer
- حذف تصادفی یک ماشین مجازی در کلاستر KVM یا VMware
- غیرفعالسازی موقت یکی از سرورهای DNS و مشاهده نحوه پاسخ سرویسهای حیاتی
اجرای این سناریوها باعث میشود تیم فنی بتواند سیاستهای Failover، Replication و Recovery را بهصورت واقعی ارزیابی و اصلاح کند.
چالشها و ملاحظات اجرایی
اجرای Chaos Engineering مستلزم رعایت اصولی است که از گسترش ناخواستهی خطا جلوگیری میکند:
- آزمایش در محیط کنترلشده:
هر آزمایش باید با محدودهی دقیق و قابلیت بازگشت سریع (Rollback) طراحی شود. - پایش بلادرنگ:
بدون مانیتورینگ دقیق و پایدار، اجرای Chaos خطرناک است. - مدیریت ریسک:
برای سیستمهای حساس (مانند بانکداری یا سلامت)، آزمایشها باید ابتدا در محیط شبیهسازیشده اجرا شوند. - هماهنگی تیمها:
Chaos باید بخشی از چرخه DevOps باشد و با اطلاع تیمهای مرتبط انجام شود. - هزینه محاسباتی:
اجرای آزمایشهای مکرر ممکن است منابع و زمان قابلتوجهی مصرف کند.
آینده Chaos Engineering
Chaos Engineering از یک رویکرد تجربی به یک استاندارد صنعتی در حال تبدیل است.
امروزه شرکتهایی مانند Netflix، AWS، Google و Shopify از این روش در چرخه DevOps خود استفاده میکنند.
تحولات اخیر در زمینهی هوش مصنوعی (AI) و AIOps نیز در حال تغییر چشمانداز این حوزه است.
در نسل جدید، مدلهای یادگیری ماشین میتوانند
بهصورت خودکار سناریوهای مناسب Chaos را شناسایی و اجرا کنند.
این رویکرد با نام AI-Driven Chaos Engineering شناخته میشود و هدف آن
بهبود مداوم پایداری زیرساختها بدون دخالت مستقیم انسان است.
همچنین ترکیب Chaos Engineering با Monitoring as Code و Infrastructure as Code (IaC)
امکان اجرای خودکار آزمایشهای هرجومرج در Pipelineهای CI/CD را فراهم کرده است.
در نتیجه، پایداری سیستم دیگر صرفاً محصول نهایی نیست، بلکه بخشی از فرآیند توسعه و استقرار محسوب میشود.
نتیجهگیری
Chaos Engineering روشی علمی برای ساخت سیستمهایی مقاومتر در برابر شکست است.
با پذیرش این واقعیت که «خرابی اجتنابناپذیر است»،
سازمانها میتوانند بهجای واکنش منفعلانه، بهصورت پیشگیرانه و برنامهریزیشده
خطاها را شبیهسازی و از آنها بیاموزند.
در زیرساختهای هاستینگ و Cloud، این رویکرد به تیمها اجازه میدهد
پایداری واقعی سرویس را نه در تئوری، بلکه در عمل بسنجند.
Chaos Engineering بهطور خلاصه، نظم در دل هرجومرج است؛
ابزاری برای آزمودن اعتماد، سنجش تابآوری و ساخت زیرساختهای مطمئن در دنیای ناپایدار فناوری.
نوین هاست یار نوین شماست
در نوین هاست، پایداری تنها یک شعار نیست، بلکه نتیجهی طراحی آگاهانه و مهندسی علمی است.
ما زیرساختهایی توسعه دادهایم که نهتنها در برابر خرابی مقاوماند، بلکه از هر بحران برای بهبود و تکامل میآموزند.
اگر بهدنبال سرویسی هستید که مفهوم واقعی تابآوری را در عمل پیادهسازی کرده باشد، هاست ابری و سرورهای مجازی نوین هاست انتخابی هوشمندانه است.





