

وقتی صحبت از پایداری سرورها و سرویسهای ابری میشود، همهچیز به مانیتورینگ ختم میشود.
مانیتورینگ همان سیستم عصبی زیرساخت است که سلامت سرورها را لحظهبهلحظه پایش میکند اما با رشد انفجاری سرویسهای ابری، میکروسرویسها و سیستمهای توزیعشده، حجم دادههای مانیتورینگ از حد درک انسانی فراتر رفته است. در گذشته کافی بود یک مدیر سرور با نگاهکردن به نمودار CPU و RAM وضعیت سیستم را تحلیل کند،
اما امروز دهها هزار متریک در هر ثانیه تولید میشوند — از لاگها تا ترافیک، از خطاهای نرمافزاری تا تاخیر در API.
اینجاست که هوش مصنوعی (AI) و بهویژه ChatGPT به میدان میآید تا مانیتورینگ سنتی را به یک سیستم هوشمند، خودیادگیرنده و پیشبینیکننده تبدیل کند.
مانیتورینگ سنتی؛ پایهای محکم اما محدود
ابزارهایی مثل Prometheus، Grafana، Zabbix و Nagios سالهاست که ستون فقرات مانیتورینگ سرورها هستند.
این ابزارها سه کار اساسی انجام میدهند:
- جمعآوری متریکها (Metrics) از سرورها و سرویسها
- ذخیره و پردازش دادهها
- نمایش آنها در قالب داشبورد و ارسال هشدار
اما این ابزارها فقط میگویند چه اتفاقی افتاده، نه چرا و چه باید کرد.
برای مثال اگر مصرف CPU ناگهان به ۹۵٪ برسد، Prometheus هشدار میدهد، ولی توضیح نمیدهد علت چیست —
آیا یک فرآیند در حال حلقهی بیپایان است؟ آیا حمله DDoS رخ داده؟ یا یک cron job اشتباه فعال شده است؟
در نتیجه تیمهای فنی زمان زیادی را صرف تحلیل دادهها، مقایسه نمودارها و یافتن ریشهی مشکل میکنند.
ورود ChatGPT و هوش مصنوعی به دنیای مانیتورینگ
مدلهای زبانی بزرگ مثل ChatGPT میتوانند با تکیه بر درک عمیق زبان طبیعی، دادههای پیچیده را تفسیر کنند.
برخلاف سیستمهای قدیمی که فقط اعداد را مقایسه میکردند، ChatGPT میتواند:
- بین الگوهای غیرعادی ارتباط برقرار کند
- دلیل احتمالی بروز خطا را توضیح دهد
- و حتی پیشنهاد رفع مشکل ارائه دهد
برای مثال، اگر از ChatGPT بخواهید دادههای زیر را تحلیل کند:
CPU: 92%
Memory: 83%
Load Average: 4.5
Disk IO: 97%
Network: 2.1Gbps
ممکن است پاسخی مثل این بدهد:
“بهنظر میرسد ترافیک بالای شبکه منجر به افزایش استفاده از CPU و Disk IO شده است. احتمالاً یک سرویس در حال لاگگیری سنگین است. بررسی مسیر /var/log و فرآیندهای فعال پیشنهاد میشود.”
این پاسخ نهتنها وضعیت را توصیف میکند، بلکه درک، تحلیل و پیشنهاد دارد — یعنی دقیقاً همان چیزی که ابزارهای سنتی ندارند.
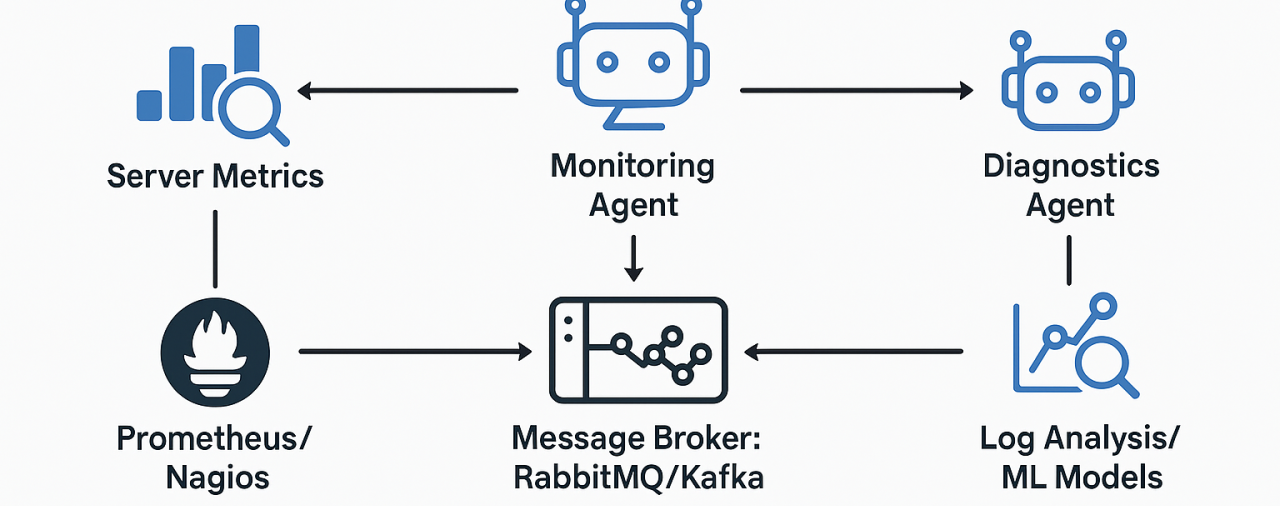
AIOps؛ DevOps با هوش مصنوعی
ورود هوش مصنوعی به عملیات زیرساخت مفهومی به نام AIOps (Artificial Intelligence for IT Operations) را ایجاد کرده است.
AIOps یعنی استفاده از مدلهای یادگیری ماشین (ML) و مدلهای زبانی (LLM) برای:
- تحلیل خودکار دادههای مانیتورینگ
- تشخیص الگوهای خطا (Anomaly Detection)
- پیشبینی مشکلات احتمالی
- و حتی واکنش خودکار به رویدادها
در این رویکرد، ChatGPT بهعنوان مغز تحلیلگر سیستم عمل میکند.
او دادههای Prometheus، ELK Stack یا Grafana را میخواند، معنا میکند و تصمیم میگیرد.
تفاوت مانیتورینگ سنتی و مانیتورینگ هوشمند
| ویژگی | مانیتورینگ سنتی | مانیتورینگ هوشمند (با ChatGPT) |
|---|---|---|
| منبع داده | متریکها و لاگها | دادهها + تحلیل معنایی |
| نوع هشدار | ثابت (Static) | پویا و متنی (Dynamic, Contextual) |
| تشخیص علت خطا | دستی | خودکار |
| پیشبینی خرابی | ندارد | دارد |
| تصمیمگیری خودکار | خیر | بله، با اسکریپت و API |
| سطح خطای هشدار | بالا (False Positive زیاد) | بسیار پایینتر |
چگونه ChatGPT دادههای مانیتورینگ را تحلیل میکند؟
ChatGPT با استفاده از درک زبانی و الگویابی میتواند دادههای عددی را هم بفهمد.
برای مثال، وقتی دادههای Prometheus بهشکل زیر ارسال شوند:
{
"timestamp": "2025-10-05T12:00:00Z",
"server": "node-4",
"cpu": 95.3,
"memory": 89.7,
"disk_io": 94.2
}
ChatGPT میتواند الگوی رشد را بررسی کرده و بگوید:
“در ۴ ساعت گذشته مصرف CPU بهطور پیوسته افزایش یافته است. احتمالاً فرآیند background جدیدی در node-4 فعال شده است. بررسی سرویس cron پیشنهاد میشود.”
به این ترتیب، ChatGPT از اعداد صرف، داستان میسازد.
معماری یک سیستم مانیتورینگ هوشمند
در یک پیادهسازی واقعی، معماری زیر رایج است:
[Node Exporters] → [Prometheus DB] → [AI Processor (Python)] → [ChatGPT API] → [Alert Manager / Slack / Telegram]
- Exporters: دادههای متریک از سرورها میگیرند (CPU, RAM, Disk, etc.)
- Prometheus: ذخیرهسازی و مدیریت دادهها
- AI Processor: اسکریپتی که دادهها را پردازش و به ChatGPT API ارسال میکند
- ChatGPT API: تحلیل هوشمند و تولید پاسخ انسانی
- Alert Manager / Messaging: ارسال هشدار به تیم فنی
پیادهسازی عملی با Python و ChatGPT API
نمونهکد ساده:
import openai, requests
openai.api_key = "YOUR_API_KEY"
def analyze_server(cpu, mem, disk):
prompt = f"""
CPU usage: {cpu}%
Memory usage: {mem}%
Disk IO: {disk}%
Please analyze the possible reason for high load and suggest fix.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role":"user", "content":prompt}]
)
return response["choices"][0]["message"]["content"]
metrics = {"cpu": 93, "mem": 82, "disk": 91}
print(analyze_server(**metrics))
ChatGPT خروجیای شبیه این تولید میکند:
“افزایش مصرف CPU و Disk نشاندهندهی فرآیندهای I/O سنگین است. بررسی فرآیندهای در حال اجرا با دستور
iotopو بهینهسازی cache سیستم توصیه میشود.”
اتصال به Prometheus API
میتوان متریکها را از Prometheus مستقیماً گرفت و به ChatGPT فرستاد:
prom_url = "http://localhost:9090/api/v1/query"
query = "avg(rate(node_cpu_seconds_total{mode!='idle'}[2m]))*100"
response = requests.get(prom_url, params={'query': query})
cpu = float(response.json()['data']['result'][0]['value'][1])
این عدد سپس به تابع analyze_server() داده میشود تا ChatGPT تحلیل کند.
تحلیل پیشبینانه با ChatGPT
در حالت پیشرفتهتر، میتوان دادههای تاریخی را برای مدل ارسال کرد تا روند آینده را پیشبینی کند:
“در ۲۴ ساعت گذشته نرخ استفاده از RAM بهصورت پیوسته افزایش یافته است. احتمال Memory Leak در سرویس PHP-FPM وجود دارد.”
این نوع تحلیل باعث میشود سیستم قبل از بروز بحران، هشدار دهد.
ساخت هوش پاسخگو (AI-driven Incident Response)
در این سطح، ChatGPT نهتنها هشدار میدهد، بلکه دستور اصلاح را هم صادر میکند.
مثلاً:
“مصرف CPU بالاست؛ ریستارت سرویس
nginxتوصیه میشود.”
اسکریپت Python میتواند با استفاده از SSH یا API سرویس، آن دستور را اجرا کند:
import os
os.system("systemctl restart nginx")
به این ترتیب، زیرساخت شما تبدیل به یک سیستم خوددرمانگر (Self-Healing Infrastructure) میشود.
مقایسه ChatGPT با ابزارهای AI Monitoring
| ابزار | نوع تحلیل | نیاز به آموزش مدل | پشتیبانی از زبان طبیعی | دقت در تحلیل علت |
|---|---|---|---|---|
| ChatGPT | زبانی و تحلیلی | ندارد (از پیش آموزشدیده) | دارد | بالا |
| Dynatrace Davis | ML اختصاصی | دارد | محدود | بسیار بالا |
| Datadog AI Engine | الگوریتمی | دارد | ندارد | متوسط |
| Splunk ITSI | مبتنی بر قوانین (Rule-based) | دارد | ندارد | خوب |
| New Relic AI | تحلیل آماری | دارد | محدود | متوسط |
ChatGPT مزیت اصلیاش در درک متنی و انعطاف بالا است — میتواند هر نوع داده را به زبان انسانی تفسیر کند.
امنیت داده در مانیتورینگ هوشمند
ارسال داده به APIهای خارجی مثل ChatGPT نیازمند ملاحظات امنیتی است.
برای محافظت از اطلاعات سرور باید:
- دادهها را ناشناسسازی (Anonymize) کنید.
- اطلاعات حساس مثل IP یا پسورد را حذف کنید.
- از Proxy داخلی یا Gateway امن برای ارتباط با API استفاده کنید.
- پاسخها را قبل از اجرا توسط انسان تأیید کنید (Human-in-the-loop).
در محیطهای حساس (مثل سرورهای مالی یا بانکی)، میتوان از مدلهای LLM داخلی استفاده کرد تا دادهها هرگز از مرز شبکه خارج نشوند.
سناریوهای واقعی استفاده در هاستینگ
۱. شناسایی حملات DDoS
ChatGPT میتواند بر اساس دادههای ترافیک (نرخ پکتها و درخواستها) تشخیص دهد آیا الگوی حمله وجود دارد یا خیر.
۲. تشخیص Memory Leak
اگر روند مصرف RAM در طول زمان افزایش یابد، مدل تشخیص میدهد که احتمال نشت حافظه در برنامه وجود دارد.
۳. تحلیل رفتار کاربران
با ترکیب لاگهای nginx، میتوان الگوهای مشکوک در درخواستها را شناسایی کرد.
۴. گزارش روزانه خودکار
ChatGPT میتواند هر صبح خلاصهای از وضعیت سرورها را برای مدیر فنی بفرستد:
“تمامی سرویسها فعال هستند. میانگین مصرف CPU در شب گذشته ۳۲٪، RAM ۴۵٪. هیچ خطای بحرانی گزارش نشده است.”
چالشها و محدودیتها
- هزینهی API در پروژههای بزرگ ممکن است زیاد شود.
- سرعت پاسخ در مقایسه با مانیتورینگ سنتی کمی کمتر است.
- وابستگی به مدل خارجی ممکن است برای سازمانهای حساس قابلقبول نباشد.
- نیاز به پالایش دادهها برای جلوگیری از تفسیر اشتباه.
اما با طراحی مناسب (Caching، Preprocessing و محدودسازی دادهها) این چالشها کاملاً قابل کنترل هستند.
آینده مانیتورینگ هوشمند
در آینده، مانیتورینگ فقط گزارش نخواهد داد — بلکه یاد میگیرد، تصمیم میگیرد و اقدام میکند.
ChatGPT و مدلهای مشابه بخشی از این تحول هستند:
- تحلیل خودکار هزاران رویداد در لحظه
- خلاصهسازی زبانی وضعیت سیستمها
- واکنش خودکار به خطاهای تکرارشونده
- و تعامل گفتوگویی با مدیر سیستم (“سلام ChatGPT، وضعیت سرور ۲ چطوره؟”)
بهزودی مدیران سیستم میتوانند در ترمینال یا حتی تلگرام، از ChatGPT بپرسند:
“وضعیت دیتابیس اصلی چطوره؟”
و پاسخ بگیرند:
“Latency دیتابیس افزایش یافته؛ کوئریهای سنگین در جدول orders مشاهده شد.”
نقشه راه پیادهسازی برای کسبوکارها
- مرحله اول: اتصال Prometheus و Exporterها
- مرحله دوم: ساخت Bridge پایتونی برای ارسال متریکها به ChatGPT
- مرحله سوم: طراحی پاسخ خودکار (Alert + Suggestion)
- مرحله چهارم: ساخت گزارش روزانهی AI با خلاصهی وضعیت
- مرحله پنجم: ایجاد Self-Healing برای سرویسهای بحرانی
این نقشه، نقطهی شروع برای زیرساختهای نوین در ایران است — بهویژه برندهایی مثل نوین هاست که در حال توسعهی سرویسهای ابری هوشمند هستند.
نوین هاست یار نوین شماست
در دنیایی که زیرساختها هر روز پیچیدهتر میشوند، تنها راه پایداری واقعی، هوشمندسازی است.
در نوین هاست ما باور داریم مانیتورینگ دیگر فقط ابزاری برای مشاهده نیست، بلکه مغز متفکر زیرساخت است. اگر میخواهید سرور شما همیشه آماده، سریع و هوشمند باشد،سرویسهای هاست ابری و سرورهای مجازی نوین هاست بهترین انتخاباند.





